
この記事を読むのに必要な時間は約 9 分です。
前回まではSelect文の基本的な使い方なり検索の仕方などを説明してきました。今回からは一気に内容を濃ゆくしていろいろな技術的な方法を小出しで出していきたいと思います。関数なども利用していきますのでその都度その都度覚えてください。
番号を振る
これ覚えると便利!ROW_NUMBER
SQLの大原則です。SQLserverに限らずデータベースは基本的には表計算ソフトではありません。マイクロソフトのExcel等が有名ですがあれはデータに対して右とか左とか上とか下とかそのような位置情報を決める事があります。枠線に色を付けたり、塗りつぶししたり。
ですが、データベースはそのような事をする物ではありません。とあるデータに対して右側左側に関係する情報が入ることはあっても上とか下とかはありません。基本、並びが保証されていないからです。
とはいっても、データとして並びに意味を持たせたい時に利用するのがこのROW_NUMBER関数です。意味を持たせるために、データに対して連番をふります。こういうのは読んでみてしっくりこないのでやってみましょう。
row_number()
まずは、テーブルを見てみます。
/****** SSMS の SelectTopNRows コマンドのスクリプト ******/
SELECT TOP (1000) [漢字都道府県名]
,[漢字市区町村名]
,[num]
FROM [test001].[dbo].[shicyouson]
この様な形で一覧がでてきます。
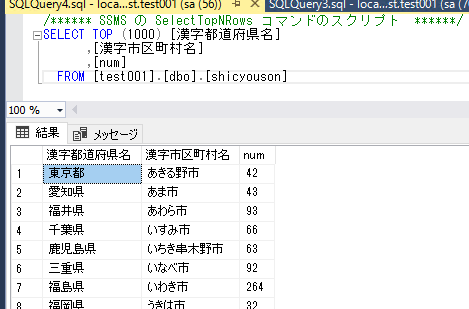
データの一番左側に連番を振ってみましょう。
関数は簡単でこんな感じです。
row_number() over(order by 漢字都道府県名)
/****** SSMS の SelectTopNRows コマンドのスクリプト ******/
SELECT TOP (1000)
row_number() over(order by 漢字都道府県名)
,[漢字都道府県名]
,[漢字市区町村名]
,[num]
FROM [test001].[dbo].[shicyouson]
連番が簡単にふることができましたね。

見切れてしまっているので、 top(1000)を消して下の方も見てみます。

1896行目まですべて表示されていますね。
●●毎に連番をふる
このrow_number()関数ですが、凄いことに特定のカラム毎に番号の振り直しをしてくれます。
方法も簡単で すべて同じ番号を振るのであれば
row_number() over(order by 漢字都道府県名)
ですが、例えば、都道府県毎に連番を振りなおしたい場合は以下のようにします。
/****** SSMS の SelectTopNRows コマンドのスクリプト ******/
SELECT
row_number() over(order by 漢字都道府県名)
,row_number() over(partition by 漢字都道府県名 order by 漢字都道府県名)
,[漢字都道府県名]
,[漢字市区町村名]
,[num]
FROM [test001].[dbo].[shicyouson]
茨城県と岡山県の県境にやってきました。
[speech_bubble type=”drop” subtype=”L1″ icon=”02ukiyoe/yukiji_R.png” name=”ゆきじさん”]ん?岡山と茨城ははなれてないか?[/speech_bubble]

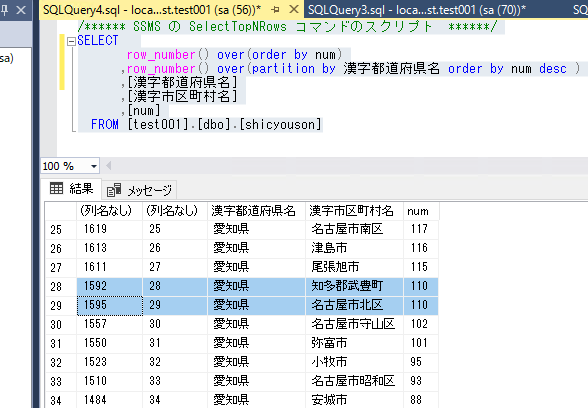
画像では一番左から順番に
- row_number() over(order by 漢字都道府県名)
- row_number() over(partition by 漢字都道府県名 order by 漢字都道府県名)
と、SQL文を書いています。
【漢字都道府県名】毎にと指定しているので、茨城県と岡山県の境で番号が新しくなっていますね。
折角なので、order by の部分に num を指定して意味のあるデータを作ってみましょう。
/****** SSMS の SelectTopNRows コマンドのスクリプト ******/
SELECT
row_number() over(order by num)
,row_number() over(partition by 漢字都道府県名 order by num desc )
,[漢字都道府県名]
,[漢字市区町村名]
,[num]
FROM [test001].[dbo].[shicyouson]
これで numには市区町村毎の住所数が入っていましたので、数字が大きい順に値が入っていますね。

これで、データ全国順位と市区町村毎の順位がわかりますね。
同率順位の求め方 (RANK ,DENSE_RANK)
運動会でかけっこをしました。1位から6位まで決める必要があります。
しかし、2位と3位の人が同じタイムでした。この時の3番目の人と4番目の人の決め方がこの
RANK、DENSE_RANKです。
まずは例でみてみましょう。
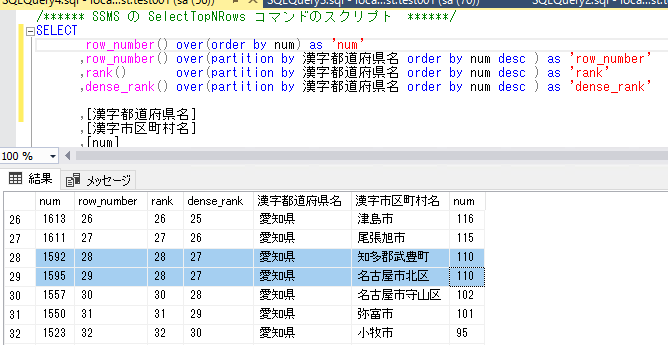
以下二つの住所は数がどちらも 110 で被ってますね。 物事に優劣を決めないといけない場合はそれぞれの区市町村で喧嘩になってしまいます。
知多郡武豊町
名古屋市北区
この様なときに、同率で同じ値をだしてくれるのが、RANK、とDENSE_RANKです
二つとも似たような内容ですので、一気に行きます。
/****** SSMS の SelectTopNRows コマンドのスクリプト ******/
SELECT
row_number() over(order by num) as 'num'
,row_number() over(partition by 漢字都道府県名 order by num desc ) as 'row_number'
,rank() over(partition by 漢字都道府県名 order by num desc ) as 'rank'
,dense_rank() over(partition by 漢字都道府県名 order by num desc ) as 'dense_rank'
,[漢字都道府県名]
,[漢字市区町村名]
,[num]
FROM [test001].[dbo].[shicyouson]
ヘッダが無いとわかりにくくなってきたのでそれぞれにつけてみました。
この例で説明しようと思いましたが、dense_rankの値がずれています。
これは、もっと上で重複が存在したためです。説明が分かりずらくなりますので上に移動します。
- 長久手市
- 名古屋市中川区
この2か所が分かりやすいですね。

違いについて一覧にしてみましたがわかりましたか?
| 関数名 | 説明 |
| row_number | 都道府県名毎の振りなおした連番。 |
| rank | 同率の場合は同じ数字を割り振る。次に続く数字は重複分を飛ばす。 |
| dense_rank | 同率の場合は同じ数字を割り振る。次に続く数字は続いた数字を採番する。 |
この様になるので 清須市は rankを利用すると15位になりますがdense_rankを使うと14位と一つ上の順番になっちゃいますね。
本日はここまで!
ちょっと一息!大人のコーナー
え・・・ 頭がおかしいセール情報を見つけました。97%OFFらしいです。
あだるてぃんな内容なので、そういうのに興味がある人だけ見てください。
※お仕事中なら見ないでください。
※帰りの電車とかでも見ないでください。

