
この記事を読むのに必要な時間は約 31 分です。
パフォーマンスチューニングについて
前置き
久しぶりにまじめなSQLのお話をしたいと思います。
しかも上級です!!
ただし、お約束な感じになりましたが、やる事ですが初級の内容となります。
今回のお題はパフォーマンスチューニングになります。ただし、パフォーマンスチューニングと言っても
みたいなカッコいい話ではなく、
みたいな現場の人が死にかかっているような泥臭い場合に使うような話です。
どちらからというと運用者の目線ですね。
本当に、やっている内容自体は初級でたいしたことないですが、
パフォーマンスチューニング
というお題が内容を上級に押し上げます。
正直この手のお題について、対応できる人は殆どいません。
何故なら、みんな知らないからです。
でも、知ってしまえばたいしたことないです。
理解できなくてもコピペだけでなとかなりますからね。
なぜパフォーマンスチューニングは必要か?答えはトラブルが発生したから
絶望的な場合を前提に考えます。
今から納品するシステムがあるから参考にしよう!みたいな人はまだ見なくて結構です。
あくまで、この内容はトラブルが発生してからが基本となります。
それは・・・
後からやる!
そうなんです。
先にできないんですよ・・・・
今回実施するパフォーマンスチューニングは
がメインの話になります。
なので、まだ動き始めていないシステムではあまり参考になりません。
例えば
みたいな話はシステムを作る前に検討をしっかり行う必要があります。
今回説明する内容は
例えば
みたいな話につなげるためだと思ってください。
因みに後からな理由は動的管理オブジェクト(DMO)を利用するからです。
動的管理オブジェクト(DMO)はSQLサーバーが動作している上での実行状況や活動状況をおなかの中にため込んでいる物だと思ってください。
以下二つに分かれます。
DMV:Dynamic Management View ⇒ ビューです。
DMF:Dynamic Management Function⇒ 関数です。
これ等を旨い事組み合わせてから問題となっているSQL文を特定していきたいと思います。
特定
まずは、これだけ
基本の状態としてこれを叩いてみてください。
select * from sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(sql_handle)

もう、見るだけで嫌になる感じがしますね。
いろいろ細かい情報をたくさん出してくれるのですが、全部は不要です。
簡単にできるところに意味があるので、不要なところはどんどん削っていきましょう!
sys.dm_exec_query_statsを使う
なんとなく↑の英語よりクエリの状態が分かりそうですね。
詳細については以下公式HPに詳しく説明が書かれていますので見てみてください。
きっと、めまいがしますから

sys.dm_exec_query_statsを使う(簡易版)
めまいが収まったぐらいだと思いますので、
必要なところだけもらっていきましょう。
last_execution_time
翻訳がなんかへんですね。最後に実行した時間です。
execution_count
![]()
単純に実行回数ととらえておきましょう。
total_worker_time

CPU時間の合計ですね。
total_physical_reads

物理的な読み取りにかかった時間の合計ですね。
total_logical_writes

今度は物理的な書き込み時間の合計ですね。
total_elapsed_time

実行に掛かった時間の合計値ですね。
total_rows

これは書いてる通り、何行返されたかの合計値ですね。
と、いう事で、必要そうな情報は
last_execution_time
last_execution_time
total_worker_time
total_physical_reads
total_logical_writes
total_elapsed_time
total_rows
ぐらいあれば十分ですね。
それではSQL文を書き換えてみましょう!
これを
select
*
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
これに
select
last_execution_time
,execution_count
,total_worker_time
,total_physical_reads
,total_logical_writes
,total_elapsed_time
,total_rows
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
↑この最後に追加 textは「sys.dm_exec_sql_text」から持ってくるので忘れずに!
こんな感じでだいぶスッキリしましたね。
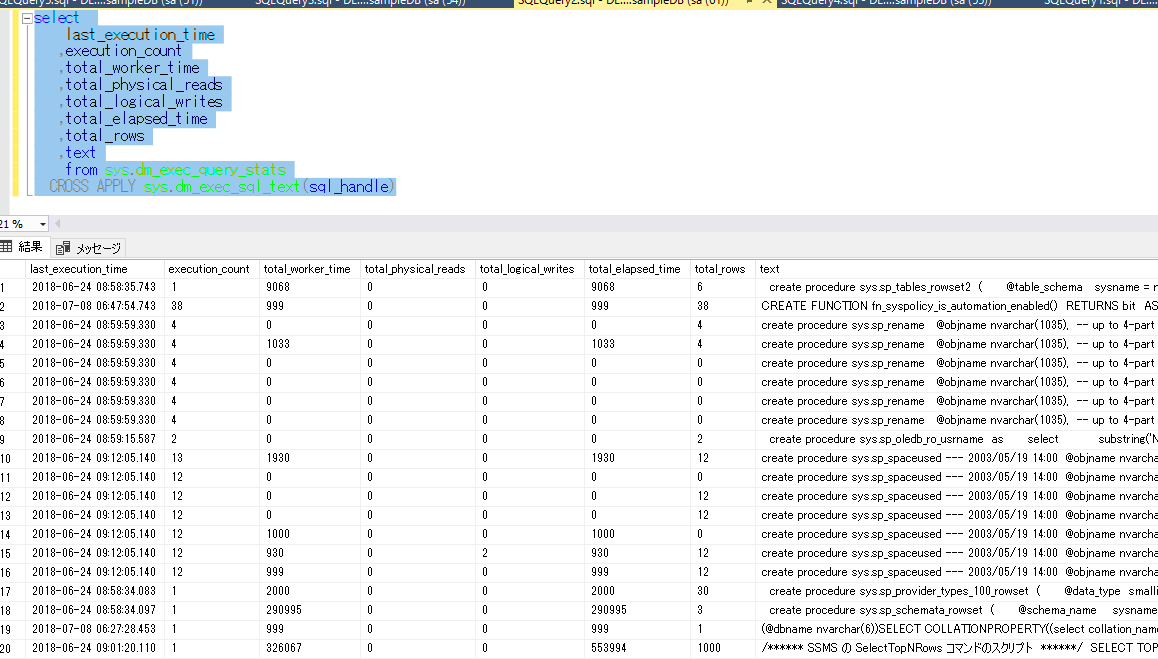
後は、これらのSQL文を組み合わせて行くだけです。
sys.dm_exec_query_statsを使う(分析)
それでは上記で取得したSQL文についてもうちょっと見やすく成型していきましょう。
- last_execution_time → 最後に実行されたタイミングなので、特定や調査の参考に
- execution_count → 実行回数なので割り算の分母に
- total_worker_time → CPU時間、演算等で利用された時間に
- total_physical_reads → 物理読み込みに必要だった時間に
- total_logical_writes → 論理書き込みに必要だった時間に
- total_elapsed_time → トータル実行時間に
- total_rows → 何行返されたか?に
- text → どのようなSQL文を発行されたか?に
この中で、last_execution_timeとtextは特定で利用できます。
その他の情報は計算で利用できますね。
なので、並び替えて・・・・
select
execution_count
,total_worker_time
,total_physical_reads
,total_logical_writes
,total_elapsed_time
,total_rows
,last_execution_time
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)

この様な感じが見やすいかもしれません。
それでは計算していきましょう
select
execution_count
,total_worker_time / execution_count / 1000 as '平均実行時間'
,total_physical_reads / execution_count / 1000 as '平均物理読込'
,total_logical_writes / execution_count / 1000 as '平均論理書込'
,total_elapsed_time / execution_count / 1000 as '平均CPU時間'
,total_rows / execution_count / 1000 as '平均取得行数'
,last_execution_time
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)

ん~ 0ばっかりでよくわからない!!小数点の一桁目までは出しておきましょう。
ちょっとだけ書式を変えましょう。
書式の変更はformat関数でやります。
select
execution_count
,format(total_worker_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均実行時間'
,format(total_physical_reads *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均物理読込'
,format(total_logical_writes *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均論理書込'
,format(total_elapsed_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均CPU時間'
,format(total_rows *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均取得行数'
,last_execution_time
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)

小数点のところまでちゃんと表示されていますね
ところで
0.1かけて10倍しています。
何やったかわかりますか?
結局1ですよね。ただ、書式中に0.1を掛け算する事によりintではなくfloat扱いに強引に変換しています。※平均取得行数は0.1のくらいはいらないかなと思いましたがノリです。
さぁ!!!!!!
ここまでおぜん立てができましたら後は解析です!!!!!!!
解析
解析開始!
それでは平均実行時間が最も大きなデータで並び替えをしてみましょう。
並び替え+大きな方を上に持ってきたいので order by desc です。
select
execution_count
,format(total_worker_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均実行時間'
,format(total_physical_reads *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均物理読込'
,format(total_logical_writes *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均論理書込'
,format(total_elapsed_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均CPU時間'
,format(total_rows *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均取得行数'
,last_execution_time
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
order by format(total_worker_time *0.1 *10 / execution_count / 1000 ,'0.0' ) desc

ん?

んん?

んは!

並びが文字列扱いやんけー
と、いう事で、急遽クエリの書き換えです。
select
execution_count
,format(total_worker_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均実行時間'
,format(total_physical_reads *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均物理読込'
,format(total_logical_writes *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均論理書込'
,format(total_elapsed_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均CPU時間'
,format(total_rows *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均取得行数'
,last_execution_time
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
order by cast(format(total_worker_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) desc
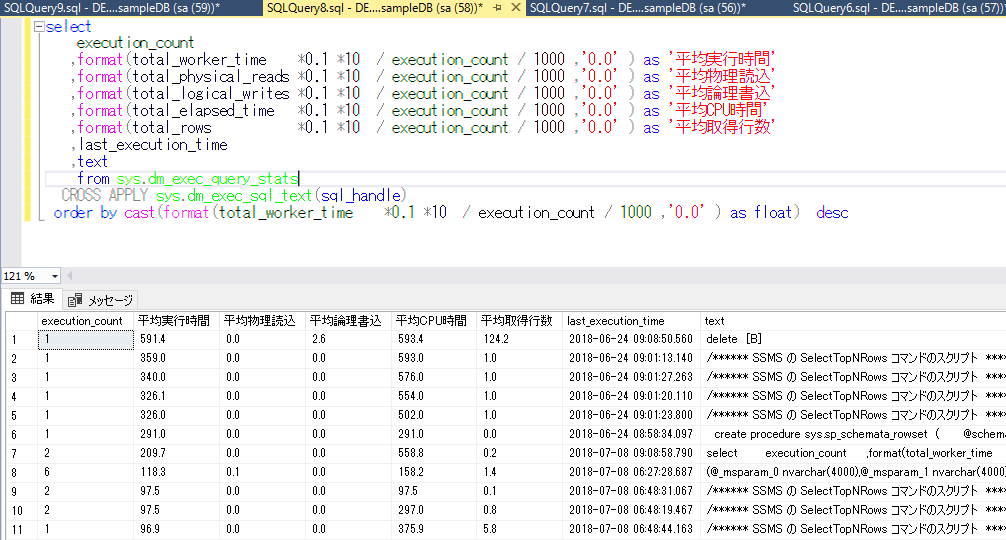
ちゃんと、並び替えがうまくいきましたね
一番最後の order byの部分で castを使って数値型に変換しただけですね。
それでは改めて解析開始!!!
解析開始!!(二回目)
と、意気込んでも良いのですが、
ちょっと、SQL文が十分汚いですよね・・・・
このまま進めても出来ますが、ここで一回スマートに対応したいと思います。
解析結果を一時テーブルに入れても良いですが、単品で実行する場合におすすめなのが
です!!
CTEが何の事かわからない場合は此方の記事を後で参照してください。

そして、記事中にも書いている通り、私は好んで使います!
良い使用例になりますね。
それではSQL文を書き換えて行きます。
変更前
select
execution_count
,format(total_worker_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均実行時間'
,format(total_physical_reads *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均物理読込'
,format(total_logical_writes *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均論理書込'
,format(total_elapsed_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均CPU時間'
,format(total_rows *0.1 *10 / execution_count / 1000 ,'0.0' ) as '平均取得行数'
,last_execution_time
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
変更後1段階目
select
execution_count
,cast(format(total_worker_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均実行時間'
,cast(format(total_physical_reads *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均物理読込'
,cast(format(total_logical_writes *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均論理書込'
,cast(format(total_elapsed_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均CPU時間'
,cast(format(total_rows *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均取得行数'
,last_execution_time
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
こんな感じで先に全部CASTしておきます。
変更後2段階目
With ANA as
(
--------------------------------------------------------------------------
select
execution_count
,cast(format(total_worker_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均実行時間'
,cast(format(total_physical_reads *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均物理読込'
,cast(format(total_logical_writes *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均論理書込'
,cast(format(total_elapsed_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均CPU時間'
,cast(format(total_rows *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均取得行数'
,last_execution_time
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
--------------------------------------------------------------------------
)
select * from ANA
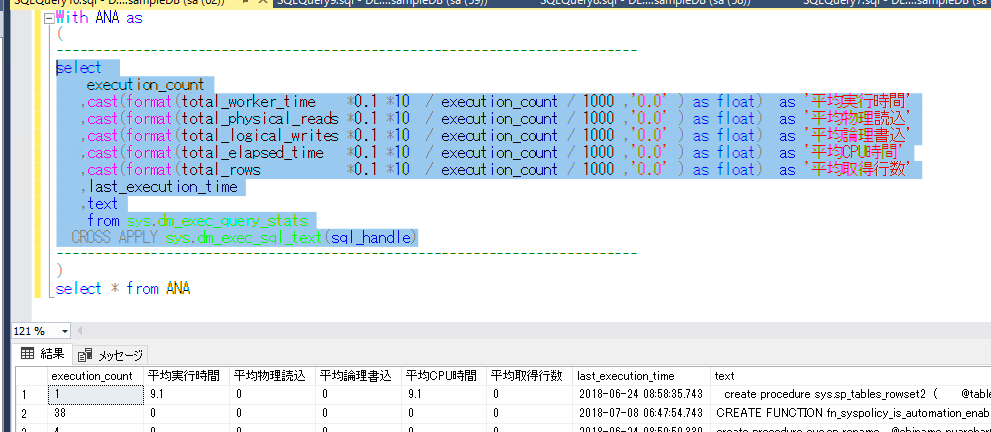
真ん中の選択している部分は変形一段階目の内容と同じです。
その上下に With区とCTE化した部分を ANAという名前にしてselectしただけです。
如何ですか?
みやすいし、Select文が物凄くシンプルになりました。
複雑な計算を沢山してきましたが、
何もせずに進める場合は目線の先はこの赤枠で囲った部分になります。

でも、CTEを使えば以下の青枠だけ見ればよくなります。
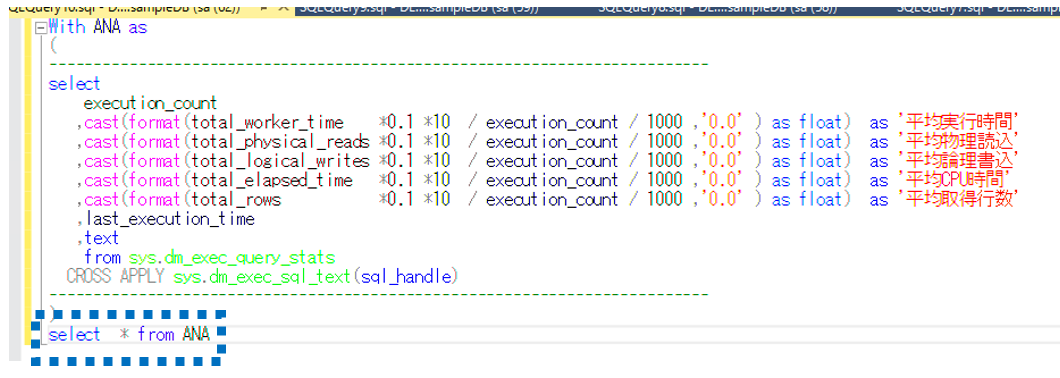
select * from ANA
だけ見ればいいんですよ!!
CTE最高!!
解析開始!!!(LASTです)
では、改めて解析してみたいと思います。
Q1
平均実行時間で時間が最もかかっているクエリは何?
A1
With ANA as
(
--------------------------------------------------------------------------
select
execution_count
,cast(format(total_worker_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均実行時間'
,cast(format(total_physical_reads *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均物理読込'
,cast(format(total_logical_writes *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均論理書込'
,cast(format(total_elapsed_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均CPU時間'
,cast(format(total_rows *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均取得行数'
,last_execution_time
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
--------------------------------------------------------------------------
)
select top 10 * from ANA order by [平均実行時間] desc
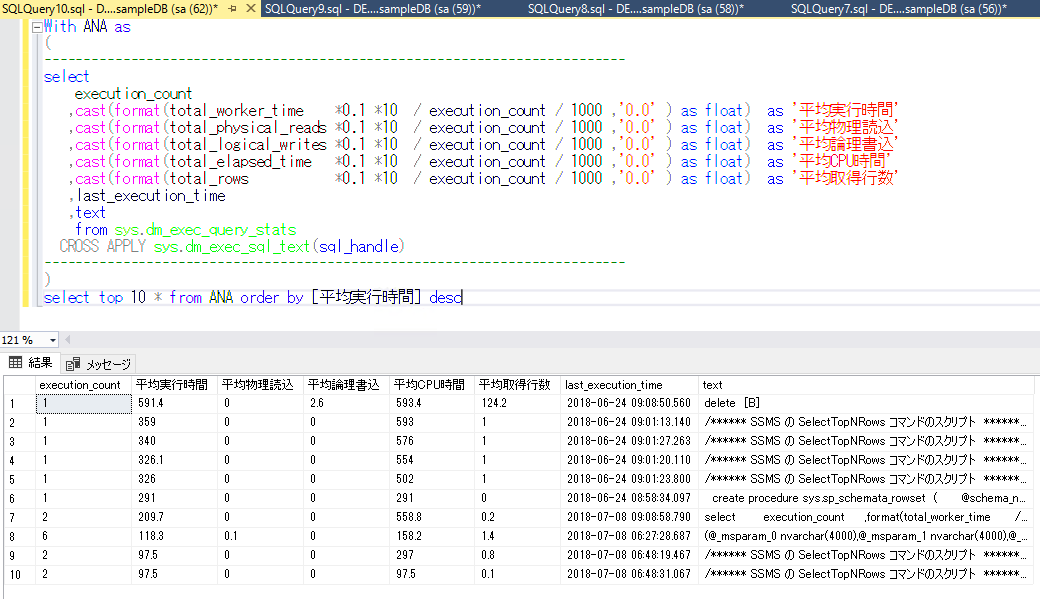
select で top 10 に絞ってみました。
また、並び替えはわかりやすく[平均実行時間]で大きい物順に並び替えています。
平均物理読込時間とか、ほかのカラムになってもやる事は一緒なので、その様な例は割愛します。
Q2
たぶん、あのSQLが悪いと思うんだけどな・・・・・
A2
textに like すればいいんですよ ※例えば、create文が怪しいと睨んでいるときは
With ANA as
(
--------------------------------------------------------------------------
select
execution_count
,cast(format(total_worker_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均実行時間'
,cast(format(total_physical_reads *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均物理読込'
,cast(format(total_logical_writes *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均論理書込'
,cast(format(total_elapsed_time *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均CPU時間'
,cast(format(total_rows *0.1 *10 / execution_count / 1000 ,'0.0' ) as float) as '平均取得行数'
,last_execution_time
,text
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
--------------------------------------------------------------------------
)
select top 10 * from ANA where text like '%create%' order by [平均実行時間] desc

create文で時間がかかるというシチュエーションは考えにくいですが、この様な形で突き止めて行くことができます。
大事な事
時間がかかっているからと言って悪ではない
殆どのSQL文はクエリの書き方なりindexの貼り方で高速化が可能ですがどうしても時間がかかっているSQL文が見つかったとします。
ですが、実行時間が物凄く長くても、平均実行時間をみると短く、実行回数がやたらと多いパターンなどもあります。
やたらと多い理由を調べたら人気コンテンツで沢山クリックされていただけでした♪とかであればあまり気にしなくてもよいですね。
また、実行時間も平均実行時間も長いが、実行されているのが月に1回だった。
その一回は月一の夜間メンテナンスで動いていた ←こんな場合はそこまで気にしなくても良いですよね。
なので、時間がかかっているからと言ってすべてがすべて悪ではないと考えてください。
本質の見極めが大事です。
以前の記事で、データの特性を見極める事が大事 だと言いましたが、似たような話で
- 利用者の意識
を見極める必要があります。
利用者が調べたいのが何なのか?
例えばスーパーの商品を例に考えて、商品の名前を調べたい人も居れば、値段で調べたい人も居ると思います。また、安い物ではなく、高い物から調べたい人も居るはずです。
SQL文はそのような仕組みに対応できるような構文になっていますか?
アプリやSQL文の制作者は何を検索させたいのか、それは利用者のニーズに合っているか
SQL文の実行履歴を確認すると、たまにそのような意図が見え隠れするようなこともあります。
たとえば、ちょっとかじって、 ワイルドカードが使える事を知っている人が 検索条件の部分に %なり* なりを入れていたら、今のSQL文を発行するアプリは利用者の気持ちがくみ取れていない可能性がある事になります。
そのような点も意識しておきましょう。
今回はここまで!

